Grass
GRASS
Target Name
Grass
Ticker
GRASS
Strategy
long
Position Type
token
Current Price (USD)
1.8
Circulating Market Cap ($M)
519.15
Fully Diluted Market Cap ($M)
1,801.97
CoinGecko
The Roots of Intelligence: Is $GRASS the most undervalued AI play?
04 Jun 2025, 03:58am
Elevator Pitch
The Grass Network is currently generating mid–8 figure annualised revenue, with the potential to double by year-end following the imminent launch of two major catalysts: multimodal data search and a new Android app. The $GRASS token captures 100% of this upside, yet has been unfairly discounted in a market crowded with dubious tokens and rightfully sceptical investors. Even under conservative assumptions, a doubling of revenue could justify a $GRASS price range of $2.97 to $5.35.
Executive Summary
As the AI hype cycle accelerates and base models become increasingly powerful and efficient, the bottleneck in development is shifting from raw compute to the availability of high-quality, multimodal data. Text data is valuable, but there is a ceiling to what can be achieved through text alone. A report by EpochAI estimates that we will finish using the current stock of all human-generated text by 2028.

Source: Epoch AI research
The new gold mine for AI models is high-quality multimodal data. Models grounded in visual, auditory, and sensory input consistently outperform their text-only counterparts in tasks requiring real-world understanding. Beyond drawing people in a Ghibli art style, these tasks also include healthcare applications (such as understanding radiology notes), surveillance (utilising drones and CCTV footage), autonomous driving and even robotics.
$GRASS stands as a unique beneficiary of this trend and is well-positioned in this upcoming shift in the AI landscape. This report outlines a dual-catalyst investment thesis along with a valuation range at the end:
Transformative Catalyst - Multimodal Data Search Launch
Grass is set to release a search product that allows AI developers to retrieve and fine-tine highly specific data across multiple modalities. This not only enhances the usability of Grass’s existing data set, but also opens new revenue channels and strengthens Grass’s positioning as the search engine for AI models.Iterative Catalyst: Android Mobile App roll out
By onboarding mobile devices to the node network, Grass broadens geographic coverage and resilience. Mobile IPs are harder to block than home static IPs, allowing the network to bypass more anti-web scraping defences. This expansion directly supports the long-term goal of enabling Live Context Retrieval (LCR).
A brief introduction to the Grass Network
AI models require large volumes of high-quality data throughout the training process, with the pretraining stage demanding the most scale and diversity. During fine-tuning, the focus shifts to smaller, domain-specific datasets that are closely aligned with the target task. Even at the inference stage, access to relevant, high-quality context can significantly improve output quality and reduce hallucinations.
Large AI labs rely on web crawlers to browse the internet and collect data for training models. As of writing, the primary players in large-scale web crawling are Google and Bing, which operate the world’s leading search engines. Building proprietary crawlers at scale is challenging for most AI companies, as many websites block traffic from data centre IPs (where these proprietary web crawlers operate from). To bypass this, web crawlers may use residential IP addresses to mimic legitimate users, making it harder for websites to block them. This strategy is limited by the number of residential IP addresses that proprietary data crawlers can get access to.
OpenAI currently has access to Bing’s search index through its partnership with Microsoft and has been working on developing its internal search infrastructure since early 2024. However, this effort has faced significant obstacles, as websites increasingly block OpenAI’s crawler, limiting its access to high-quality, up-to-date multimodal data.
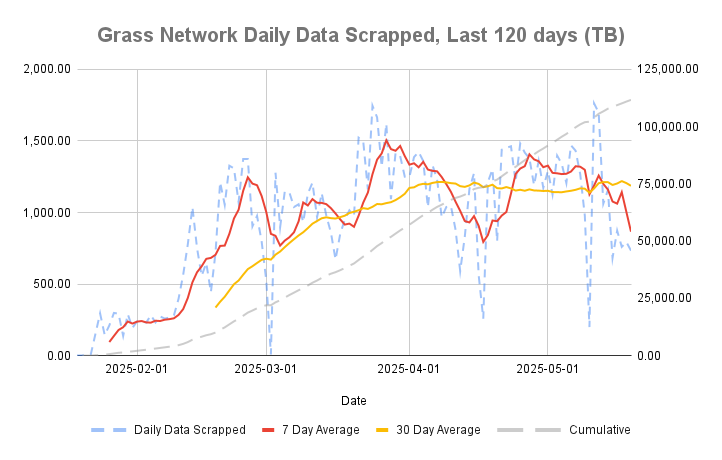
Source: https://www.grassfoundation.io/network/stats
Grass Network addresses this challenge by incentivising millions of real users to share their residential IP addresses, allowing it to bypass website restrictions that typically block data centre-based web crawlers. Based on the last 120 days of data, the network scrapes an average of 1.2 PB of data daily. The ultimate goal of the Grass Network is to launch its Live Context Retrieval (LCR) product, which enables AI models to access fresh, real-time web data during inference, potentially disrupting the current duopoly and positioning itself as the search engine for AI models.
Why $GRASS is bullish
What is Multimodal Search?
Multimodal search refers to the ability to search across various types of data (such as text, images, video, and audio) using multiple forms of input beyond just text. A basic but illustrative example is uploading a photo to Google Image Search and receiving relevant video results. This approach dramatically improves the relevance and accuracy of search results for human users. For instance, attaching an image of a pair of shoes you saw in a store will get you better online results than simply typing “white sneakers with a tick at the side”.
This same advantage applies to AI models: multimodal search enhances inference quality by providing richer context. For example, asking ChatGPT about a rash while attaching an image enables the model to reason more effectively, thereby reducing the likelihood of overly broad or inaccurate responses. This capability is especially critical in robotics, where real-time multimodal search (combining camera feeds, environmental audio, and other sensory data) is essential for understanding surroundings and making informed decisions.
Why Multimodal data search is a transformative catalyst for Grass

Grass network Stats (extracted on 29th May 2025)
Since its launch, the Grass network has amassed a substantial volume of data essential for training AI models. A notable contribution is the Video-Audio Large Interleaved Dataset (VALID), developed in collaboration with Ontocord and LAION. VALID comprises approximately 720,000 Creative Commons-licensed videos sourced from YouTube, processed into synchronised audio-video-text records for machine learning research.
This dataset is significant as it represents the first publicly available multimodal dataset where video, audio, and text are interleaved (the data shows how sound, text and video should look across time). This structure enables models to learn the relationships between visual and auditory elements over time, which is crucial for applications like video generation and robotics.
For instance, consider the advancements in AI video generation models. Google DeepMind's Veo 3 can generate high-resolution videos with synchronised audio, including dialogue and ambient sounds, directly from text prompts. In contrast, OpenAI's Sora currently generates videos without native audio, requiring users to add sound manually. The interleaved nature of datasets like VALID provides the necessary training data for models to produce coherent audiovisual outputs, enhancing their applicability in real-world scenarios.
Moreover, VALID holds significant promise for robotics research, particularly in developing Vision-Language-Action (VLA) models. VLA models make use of visual and text inputs to control robotic movements. These models rely on synchronised multimodal data to understand and execute tasks in dynamic environments. The interleaved format of VALID allows robots to better interpret and respond to complex instructions that involve both visual and auditory cues, thereby improving their performance in real-world applications. The access to a large decentralised network of residential IP addresses allowed Grass to bypass blocking attempts from video hosting websites like Youtube (which Google owns) and democratised access to high-quality video training data sets. This is likely only the beginning of what Grass can do for multimodal data.

Andrej on the importance of multimodal search and demand from robotics companies (Tweet)
While possessing a vast video dataset like that of the Grass Network is invaluable, the true potential of such data is unlocked through effective multimodal search capabilities. This functionality allows AI developers to extract specific subsets of data tailored for fine-tuning models to particular tasks or styles. For instance, when aiming to fine-tune video generation models for specific anime genres, multimodal search enables the retrieval of relevant video clips, associated audio, and textual metadata, ensuring that the model learns from contextually rich and stylistically consistent examples. Getting such data allows a model to give more relevant and consistent outputs.
The integration of Grass Network's extensive data collection with robust multimodal search positions it as a formidable resource for AI development, especially for entities lacking exclusive data partnerships with major search engines like Bing or Google. By facilitating access to diverse and contextually relevant datasets, Grass empowers a broader range of developers to train and refine AI models with greater precision and efficiency. Inferring from the founder’s public Discord messages, Multimodal search is expected to launch sometime between the end of May and Early June. This is likely a key repricing event for Grass as it makes all the data it has scraped even more valuable and marketable to large AI labs, opening new revenue streams. The public acknowledgement of using the data set will also prove the legitimacy of Grass’s business model and product offerings, helping put to rest some doubts that liquid market participants have regarding $GRASS revenues.

Grass Discord Messages from Drej under General
Why the upcoming Android app is an iterative catalyst for Grass

0xPingu_ on Grass App (Tweet)
Members of the Grass community would have likely seen early users sharing their experience with the Grass mobile application. This mobile app is a major step forward for the network, as it significantly expands the number of residential nodes contributing to the bandwidth of the system. More nodes mean broader geographic coverage and greater capacity for scraping fresh data from the public web, particularly from sites that attempt to block data centre crawlers.
This expansion is key to enabling Grass’s long-term goal: Live Context Retrieval (LCR). LCR gives AI models a real-time search and reasoning layer, allowing them to pull the most up-to-date, relevant data for inference. This capability is especially powerful for:
Time-sensitive questions, such as: “Will an ETH staking ETF be approved soon?”
Domain-specific lookups, like: “What are the latest research findings on GLP-1 receptor agonist side effects?”
Multimodal lookups, like enabling a robot to better understand its surroundings in real time, so that he/she/it can better plan how to fold your clothes.
Beyond data coverage, the mobile app also helps reduce operational risk. Mobile phones on cellular networks are assigned dynamic public IP addresses by their mobile carriers. These IPs often rotate and are commonly shared across many users through Carrier-Grade NAT (CGNAT). This is in contrast to home Wi-Fi setups, where multiple devices typically share a single public IP (assigned to the router), while each device has a private IP within the local network (e.g., 192.168.x.x). You can read more about it here.
This is important because blocking a mobile IP address is risky for websites, since it could affect hundreds or even thousands of legitimate mobile users. As a result, websites will be more reluctant to block mobile traffic. This makes mobile devices running the Grass application harder to detect and block, reducing the risk of Grass losing access to key data sources.
Grass Network’s fair valuation range
Investors have expressed scepticism regarding Grass’s reported revenues, particularly after the founder disclosed in a Delphi interview that the company is generating “mid 8-figure revenue” on an annualised basis. While specific figures were not provided, this claim suggests annual revenues in the range of $50 million to $90 million.
Given the substantial investments AI companies make in data acquisition, such revenue figures are plausible. For instance, Amazon recently entered into a multi-year AI licensing agreement with The New York Times, granting access to a broad range of editorial content for integration into Amazon-owned products and AI experiences. Similarly, OpenAI secured a $250 million, five-year deal with News Corp (the parent company of The Wall Street Journal) to access its content for model training and deployment.
A report from DMD of Aretes Capital briefly addressed the challenges in publicly verifying such revenues, noting that client confidentiality and pricing power concerns often prevent companies like Grass from disclosing detailed financial information. This lack of transparency can lead to undervaluation, as investors may discount the company’s worth due to perceived risks.

AI Valuation multiples from Aventis Advisors
The industry average Enterprise Value to Revenue (EV/Revenue) multiple for private AI companies stands at approximately 29.7x. Applying this multiple to Grass’s estimated revenues suggests a valuation range between $1.49 billion and $2.67 billion. This indicates a potentially significant upside if the company’s revenue claims hold true and if the market recognises its value appropriately.
It is worth noting that the “mid 8-figure” revenue was declared in March of 2025 before the launch of their multimodal data search and increase in the number of nodes through the Grass Mobile application. With these developments, I anticipate network revenues will double over the next year, and potentially grow 3-4x within two years following the launch of the LCR product.
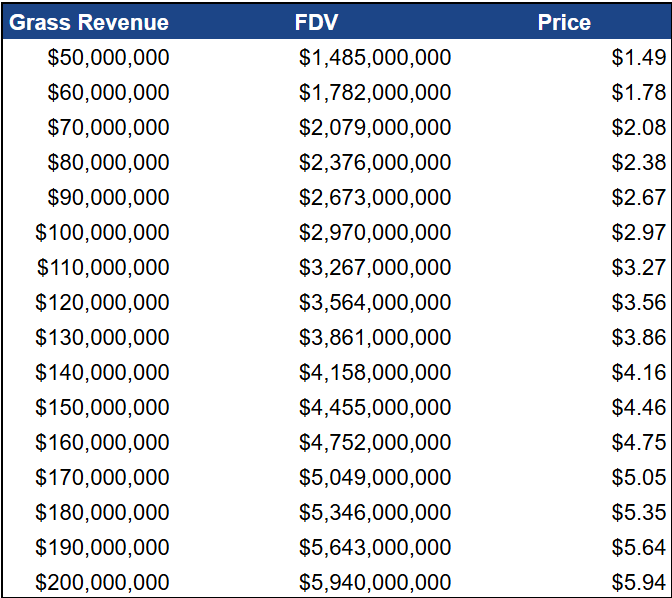
A range of valuations for Grass
Importantly, Andrej has publicly stated that “100% of the commercial contracts face the foundation directly, and not the labs entity”. This structure ensures that the $GRASS tokens are the sole beneficiary of all future revenue streams and net profits. As of today, the Grass Network has been reinvesting its revenues into capital intensive infrastructure to support long-term growth such as building an exabyte-scale data centre.

A tweet from Andrej to a supportive investor on CT

DePIN's annual revenues and valuations
However, when compared to crypto DePIN (Decentralised Physical Infrastructure Networks) projects, valuation metrics can be less reliable due to limited data and varying disclosure standards. Many projects in this space do not generate substantial revenue (if any), making direct comparisons challenging. Here is a quick summary of how the numbers were calculated:
Render: Utilising its Burn-and-Mint Equilibrium (BME) model, Render burns tokens equivalent to the USD value of rendering jobs submitted by users. Year-to-date weekly burn data and prices were used to calculate the annualised revenue.
Aethir: They tweeted that they are making 126m in revenue a year
Geodnet: Their website states their ARR number
These examples illustrate the diverse revenue models and disclosure practices within the DePIN sector, highlighting the challenges in making direct comparisons. While investor doubts about Grass’s revenue legitimacy are understandable given the lack of detailed disclosures, the context of substantial data acquisition spending by AI companies and the company’s positioning in the market suggest that its revenue claims are plausible. If these revenues are accurate and the company continues to grow, there is a potential for significant valuation appreciation, presenting an asymmetrical payoff for investors.
Conclusion
With several upcoming catalysts poised to expand Grass’s revenue streams and strengthen its technical credibility, I believe $GRASS is on the verge of a significant market repricing. As one of the few crypto-native projects offering real exposure to AI and robotics backed by a defensible moat, Grass stands out as one of the most compelling opportunities for investors in the space.
•
•
•
Affiliate Disclosures
- The author and/or others the author advises currently hold, or plan to initiate, an investment position in target.
- The author does not hold an affiliated position with the target such as employment, directorship, or consultancy.
- The author is not being compensated in any form by the target in relation to this research.
- To the best of the author’s knowledge, the information provided here contains no material, non-public information. The accuracy of the information is the responsibility of the reader.
Neither BIDCLUB nor PHATPITCH LLC represents or endorses the accuracy or reliability of any advice, opinion, statement or other information displayed, uploaded, or distributed through BIDCLUB by any user, information provider, or other party. PHATPITCH LLC is not a broker, a dealer, or investment adviser. Nothing in BIDCLUB constitutes an offer or a solicitation to buy or sell any securities. BIDCLUB prohibits the sharing of material non-public information (MNPI), but assumes no responsibility for member conduct or associated risks. Nothing in BIDCLUB is intended as specific investment advice and no individual should make any investment decision based on any recommendation or analysis provided on BIDCLUB. You acknowledge that any reliance upon any such opinion, advice, statement, memorandum, or information shall be at your sole risk, and you bear sole responsibility for your own research and investment decisions. See full
Terms and Conditions.
Hey man thanks for the coverage on $GRASS, just a couple Q's on my end:
- Can you help me break down a little bit on how exactly GRASS achieves its mid-double-digit million revenue? Is it from a handful or a bunch of customers paying them for the data?
- I'm a little surprised that they are so coy about disclosing it publicly (as opposed to a lot of other companies that actually make money in crypto. Why do you think they are so secretive around these numbers and public disclosure? Are they going to change that any time soon?
- Are they selling any tokens to fund themselves? Or are they funding themselves via the cash + funds raised from the VC (so no token selling pressure?)
- Eventually what's the token value capture? I'm assuming there's no equity component to the story?